Jenkins CI server was selected as the main CI tool to collect all application components into one biggest package to further distribution.
Jobs for each component have own infrastructure, tests, build steps, etc
This CI scheme we had to support as much as possible by using only automatic deployment by using official Jenkins its docker image (https://hub.docker.com/r/jenkins/jenkins/). We had to provide full portability to provide quick movement if it required with saving builds info in backup copies. Builds numbers were used to mark packages versions.
By using fixed docker environment we provided to the DevOps team ability to deploy the similar Jenkins environment with all jobs, that had production and could be sure, that development environment had the same environment, the same list of plugins without any manual changes. If we required to add new plugin we used docker run instruction to install it into the Jenkins custom docker image for our project.
For generation Jenkins jobs we used https://docs.openstack.org/infra/jenkins-job-builder/
All this spets were fixed in groovy code that was used for provisioning Jenkins.
Jenkins jobs in templates were stored in GitHub repo, that provided us full control by jobs changes.
When we could, we made parallel execution of builds steps and this scheme is better to see in modern Jenkins Blue Ocean interface.
For unloading master node we connected to Jenkins static Jenkins slave nodes, that were used for running tests, installing an application and other difficult operation, that required a lot of resources and could take a lot of CPU and memory on the master node. These Jenkins slave nodes were switched off by default and could be launched by Jenkins master on demand and shut down where they were not required yet to save cloud credits. For this purpose, all jobs that were generated had a special node marker.
For designing jobs we used groovy pipeline code, that provides us the flexibility of builds designing.
We used third-party service integration as much as possible:
- Mark commits by builds status
- Check code by SonarQube
The biggest pipeline parallel jobs that were designed by our team is running tests against application instances and the next picture we achieved.
By using parallel approach and running tests separately we decreased the time of basic testing from 1h 30m up to 20 minutes that provide developers information about testing status more quickly than before. We use possible channels to notify team about builds status: email, slack, GitHub commit status and other. The same we also did against bitbucket.
Our experience

Laravel applications often contain a large number of files that need to be interpreted with each server request. In my project, the number of files reached 20,000, causing significant disk load and affecting page load speed. The solution to this problem was using PHP OPcache, which significantly reduced IOPS and doubled the speed of request […]
Our experience

Challenge: We deployed an AWS ECS Cluster using Terraform, with multiple application components communicating via AWS Network Load Balancer (NLB). The NLB was chosen because the application used a custom protocol (AKKA Cluster Discovery Protocol over TCP), which AWS ALB does not support. Initially, everything worked fine with an external-facing NLB, but the client requested […]
Our experience
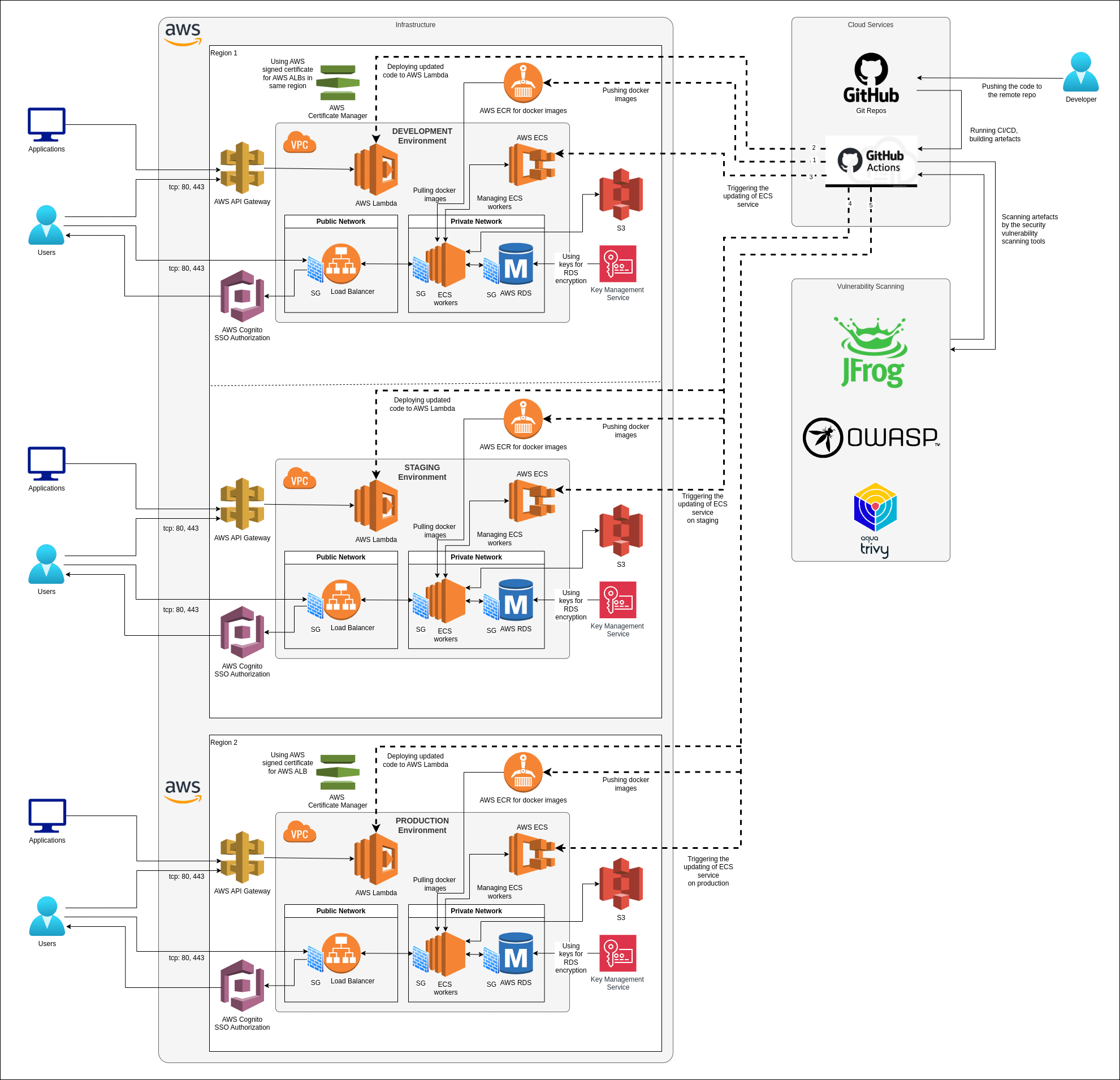
The provided diagram illustrates three similar environments: development, staging, and production. Development and staging are hosted in the same AWS region, while production can optionally be deployed in a region of choice. The infrastructure includes the following components: AWS ECS (or optionally AWS Elastic Beanstalk) for application orchestration. AWS RDS for relational database management. AWS […]